¿Qué es EvALL 2.0?
EvALL 2.0 (Evaluate ALL 2.0), es una herramienta de evaluación para sistemas de información que permite evaluar un conjunto extenso de métricas que abarcan multitud de contextos de evaluación, entre los que se incluyen clasificación, ranking, o LeWeDi. EvALL 2.0 está diseñada sobre los siguientes conceptos: (i) persistencia, el usuario puede guardar evaluaciones, así como recuperar evaluaciones pasadas; (ii) replicabilidad, todas las evaluaciones son realizadas siguiendo la misma metodología, por lo que son estrictamente comparables; (iii) efectividad, todas las métricas se engloban bajo la teoría de la medida y han sido doblemente implementadas y comparadas; (iv) generalización, la generalización viene dada por el uso de un formato estandarizado de entrada que permita al usuario evaluar todos los contextos de evaluación.
¿Para qué sirve EvALL 2.0?
El objetivo final de EvALL 2.0 es proporcionar una plataforma de evaluación avanzada de sistemas de PLN donde en solo cuatro pasos, cualquier usuario, independientemente de su perfil y experiencia, pueda evaluar sus modelos. En concreto, el usuario solo tendrá que: (i) subir el archivo gold standard; (ii) subir uno o varios archivos con las predicciones de sus modelos; (iii) seleccionar las métricas deseadas; (iv) pulsar el botón Evaluar. En concreto, EvALL permite:
- Realizar evaluación contra un gold standard que está en el Repositorio EvALL 2.0.
- Realizar evaluación subiendo tu propio gold standard.
- Visualizar los resultados tanto textual como gráficamente mediante el Dashboard de evaluación.
- Seleccionar entre un amplio conjunto de métricas que abarcan 6 contextos de evaluación diferente.
- Analizar tus evaluaciones y análisis desagregados en detalle mediante la consola PyEvALL y el informe PyEvALL.
- Publicar tus resultados en el repositorio EvALL 2.0.
- Publicar tus gold standard en el repositorio EvALL 2.0.
¿Qué métricas incluye EvALL 2.0?
EvALL dispone diferentes métricas a utilizar en función del contexto de evaluación: Accuracy, System Precision, Kappa, Precision, Recall, F-Measure, ICM (Information Contrast Measure), ICM Norm, Precision at k, R Precision, MRR, MAP, DCG, nDCG, Cross Entropy, ICM-Soft y ICM-Soft Norm.
¿Qué contextos de evaluación incluye EvALL 2.0?
EvALL 2.0 permite evaluar en los siguientes contextos de evaluación:
- Clasificación mono-label sin jerarquía: contexto de evaluación en el que a cada instancia se le asigna una clase objetivo, y solo una. Además, las clases no tienen orden o jerarquía entre ellas y todas tienen la misma relevancia. Las métricas disponibles para este contexto son: Accuracy, System Precision, Kappa, Precision, Recall, F-Measure, ICM, ICM Norm.
- Clasificación multi-label sin jerarquía: contexto de evaluación en el que cada instancia se le asigna una clase, o varias, de entre un conjunto de clases objetivo. Además, las clases no tienen orden o jerarquía entre ellas y todas tienen la misma relevancia. En este contexto se puede evaluar con las métricas Precision, Recall y Fmeasure.
- Clasificación mono-label jerárquica: contexto de evaluación en el que a cada instancia se le asigna una clase objetivo, y solo una. Además, las clases tienen una relación jerárquica, de forma que los errores entre clases del mismo nivel jerárquico representan fallo menor que los errores entre clases de niveles jerárquicos diferentes. En este contexto se encuentran disponibles las métricas ICM e ICM Norm.
- Clasificación multi-label jerárquica: contexto de evaluación en el que a cada instancia se le asigna una clase, o varias, de entre un conjunto de clases objetivo. Además, las clases tienen una relación jerárquica, de forma que los errores entre clases del mismo nivel jerárquico representan fallo menor que los errores entre clases de niveles jerárquicos diferentes. En este contexto se pueden utilizar las métricas ICM e ICM Norm.
- Ranking: en el contexto de evaluación de ranking, las métricas tienen como objetivo cuantificar en qué medida un ranking producido por los sistemas es compatible con los valores de relevancia asignados en el gold standard.. En este contexto hay disponibles las siguientes métricas: Precision at K, R Precision, MRR, MAP, DCG y nDCG.
- LeWiDi: contexto de evaluación en el que cada instancia tiene una distribución de probabilidades para todas las clases posibles. Para evaluar en contextos de desacuerdo, se encuentran disponibles las métricas Cross Entropy, ICM Soft e ICM Soft Norm.
¿Qué necesito para usar EvALL 2.0?
EvALL 2.0 es una aplicación orientada a usuarios registrados, debido fundamentalmente a la necesidad de controlar los procesos de evaluación en el servidor debido al consumo excesivo de recursos. Para ello solo hay que rellenar un pequeño formulario con unos datos básicos y un correo electrónico. El proceso se realiza en dos pasos, en primer lugar el usuario debe cumplimentar el formulario de registro y enviarlo, y en un segundo paso dicha solicitud debe ser aceptada por un administrador.
¿Cómo puedo registrarme?
Si se posee una cuenta del grupo de aplicaciones ODESIA, únicamente se tiene que pulsar en el elemento de Login/Registro del menú principal y utilizar las credenciales. En caso de no tener ninguna cuenta, en la misma pantalla de Login se puede ir a la opción de “Crear nueva cuenta” y rellenar los datos obligatorios “Dirección de correo electrónico” y “Nombre de usuario”. A continuación se recibirá un correo electrónico con la contraseña.
¿Cómo puedo evaluar mis modelos con EvALL 2.0?
Para evaluar un archivo de resultados en EvALL, el primer paso necesario es crear una evaluación. Para ello, en la pantalla de “Mis evaluaciones” es necesario pulsar en “Nueva evaluación” y seleccionar si se trata de una evaluación utilizando un gold standard incluido en el repositorio o en un gold standard subido por el usuario.
- Gold standard incluido en el repositorio: al seleccionar gold standard de repositorio, todas las definiciones necesarias se obtienen directamente del repositorio almacenado en el sistema, por lo que únicamente se tiene que buscar el gold que se quiere utilizar.
- Gold standard subido por el usuario: esta opción permite crear un gold standard a partir de un archivo personalizado, para ello es imprescindible que el formato del archivo cumpla con los requisitos explicados en este mismo FAQ. Una vez subido se debe seleccionar el formato de archivo y jerarquía si fuera necesario.
Una vez creada la evaluación, para evaluar un archivo de resultados, en el Dashboard de resultados, se muestra un formulario en la columna izquierda en el que se puede subir uno o varios archivos de predicciones y a continuación seleccionar con que métricas se quiere evaluar dentro del listado. Finalmente el botón “Evaluar” inicia el proceso de evaluación el gold standard seleccionado previamente y los resultados se mostrarán tanto en la tabla de resultados como en las gráficas.
EvALL 2.0 almacena automáticamente todas las evaluaciones realizadas por un usuario, por lo que en cualquier momento se puede volver a acceder a ellas para su gestión. Mediante la página “Mis evaluaciones” un usuario puede acceder a sus evaluaciones pasadas para visualizar sus resultados, evaluar nuevos sistemas y compararlos con los anteriores, borrar evaluaciones almacenadas en la base de datos, o crear nuevas evaluaciones.
¿En que formato tienen que estar los archivos de gold standard y de predicciones?
El formato por defecto para EvALL es json dada su gran versatilidad así como la facilidad para controlar posibles errores según el formato. Para ello se ha creado un schema en el que se definen los atributos permitidos, así como sus tipos, declarando para cada uno de ellos si son requeridos o no.

En concreto, cada atributo representa: test_case: en formato string un experimento o caso de uso determinado, pudiendo ser, por ejemplo, diferentes ejecuciones de un algoritmo de clasificación, o diferentes queries en un contexto de ranking. id: admite tanto formato string o int, pero tiene que ser el mismo para el archivo de predicciones y de gold standard. El identificador unívoco de la instancia en el dataset. value: este campo representa el valor asignado a cada item y cuyo tipo variará dependiendo del contexto de evaluación aplicado. Por ejemplo, para clasificación mono-label, el elemento estará compuesto por un string, mientras que para clasificación multi-label, el elemento estará compuesto por un vector de strings.
Este formato se puede adaptar para los diferentes contextos de evaluación, a continuación se muestran ejemplos del formato en función del contexto:
Formato Clasificación monolabel
Este formato es el formato típico de las tareas de clasificación monolabel donde cada item tiene una única clase asociada. En este formato la etiqueta será cualquier cadena de caracteres. Un ejemplo para este formato es:

En ejemplo mostrado se puede ver que el array está formado por tres elementos pertenecientes a un mismo test_case, "EXIST2023", con tres identificadores diferentes (I1, I2 e I3), y tres clases objetivo diferentes ("A", "B" y "C").
Formato Clasificación multilabel
El formato de clasificación multilabel es aquel en el que cada item puede estar clasificado con una o varias clases objetivo. Por este motivo, el formato de los archivos a enviar para este formato están compuestos de los mismos elementos que en el caso anterior, con la diferencia de que el atributo "value" en este caso es un array de elementos. Estos elementos a su vez deben ser cadenas de caracteres. Un ejemplo para este formato se puede encontrar es el siguiente:
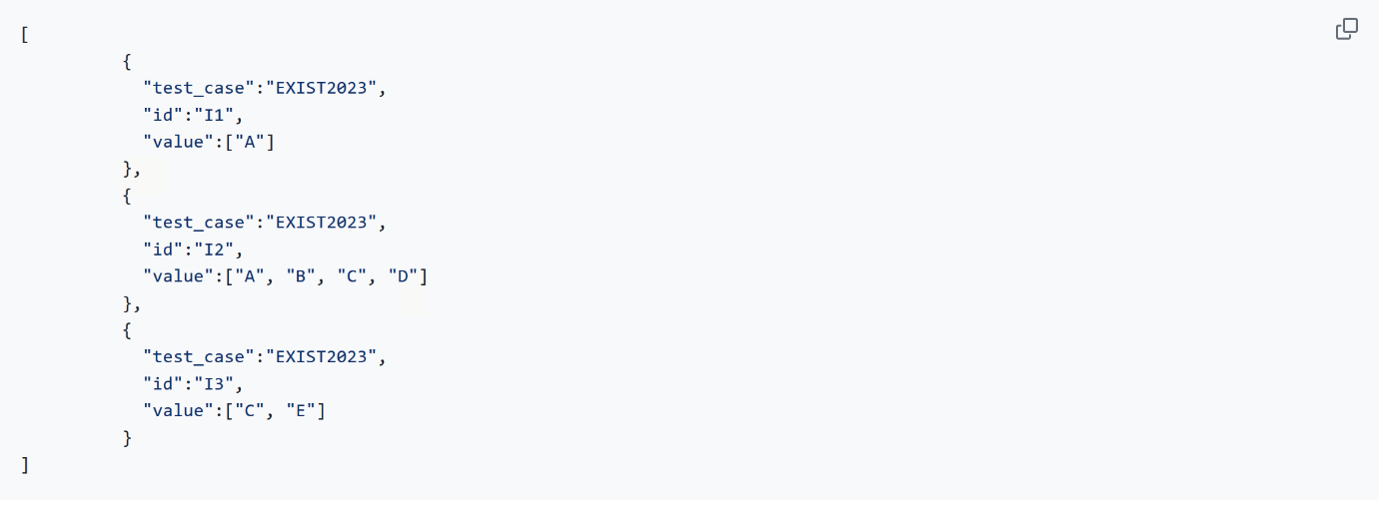
Como se puede ver en el ejemplo, el archivo está formado por un array de objetos json con tres elementos con los mismo campos en que en el caso anterior, pero con la diferencia, en este caso, de que el atributo "value" esta compuesto por un array con las clases objetivos de cada item.
Formato Clasificación con desacuerdos
El formato de clasificación con desacuerdos permite asignar a cada elemento del dataset una distribución de probabilidades asociada a cada clase. Es decir, en lugar de seleccionar una única categoria absoluta para cada item, la distribución de etiquetas por anotador es asignada a cada elemento. En el siguiente ejemplo, se puede ver el formato utilizado por EvALL es similar a los anteriores, con la salvedad de que en este caso el atributo "value" es representado con un diccionario Python donde cada elemento representa una clase objetivo y su valor la probabilidad de que sea asignado. Notese, que en el caso de clasificación con desacuerdo monolabel la suma para cada elemento debe sumar 1, mientras que para clasificación multilabel no es necesario.

Formato Ranking
En el formato del contexto de evaluación ranking cada item tiene asignado un valor indicando la posición de ordenación en el ranking, en el caso de las predicciones, y el valor de relevancia, en el caso del goldstandard. Como se puede observar en el siguiente ejemplo, el formato es exactamente el mismo que en los casos anteriores, pero con la diferencia de que en este caso el valor del atributo "value" esta formado por números que representan, en cada caso, la ordanción o relevancia del item.
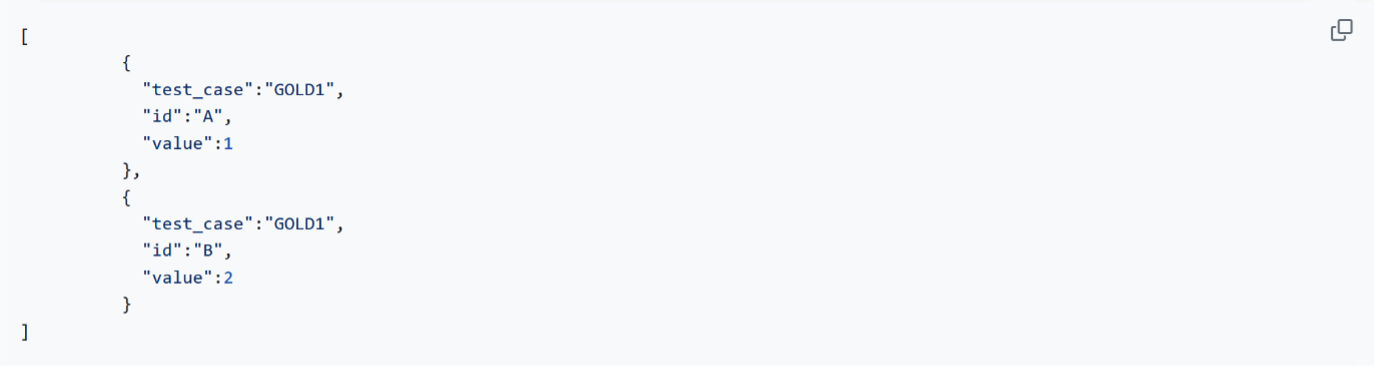
En la imagen se muestran las prediciones de un sistema de ranking que ha indicado que el item con identificador "A" tiene asignada la posición 1 del ranking, mientras que el item con el identificador "B" tiene asignada la posición 2 del ranking.
